
tg-me.com/knowledge_accumulator/22
Last Update:
Exploration by Random Network Distillation [2018]
Как нам решить проблему исследования среды и награждать агента за посещение новых состояний?
1) Берёте две случайные свёрточные сети. Одна - учитель, другая - ученик.
2) На встречающихся данных тренируете ученика предсказывать то же, что и учитель. Учителя не трогаем.
3) Если наша ошибка высокая, значит мы подали более новое состояние, если низкая, то более баянистое.
4) Добавляем MSE предсказания ученика с весом к обычной награде из среды.
Удивительно на первый взгляд, но результат прорывной - даже без настоящей награды нейросеть может научиться бродить и исследовать "мир" в игре с врагами и препятствиями.
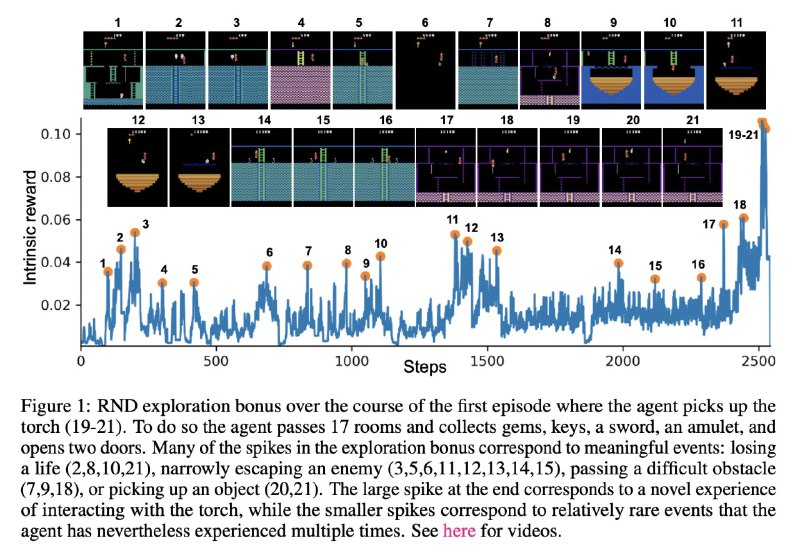
На картинке можно посмотреть иллюстрацию того, как оно работает в реальности, с пояснениями, наслаждайтесь :)
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/22